Mind the Patch Gap: Exploiting an io_uring Vulnerability in Ubuntu
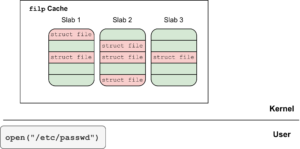
By Oriol Castejón Overview This post discusses a use-after-free vulnerability, CVE-2024-0582, in io_uring in the Linux kernel. Despite the vulnerability being patched in the stable kernel in December 2023, it wasn’t ported to Ubuntu kernels for over...
Read More